こんにちは、エキサイト株式会社でインターンをさせていただいている木下です。
今回は、2〜3月の2ヶ月間、就業型インターンをさせていただいて学んだことをご紹介します。
自己紹介
趣味は、アニメ・漫画を見ること、サッカーをすることです。
高校3年で、授業でプログラミングに触れて興味を持ち、情報工学科に入学しました。
大学2年から、アプリ開発に興味を持ち、9月にエキサイト株式会社でのハッカソン型インターンの「Booost」に参加しました。
そして、エキサイト株式会社に就業型で働いてみたいと思い、2〜3月の2ヶ月間、就業型インターンをさせていただきました。
技術的なことでは、アプリ開発に広く興味があり、LaravelやRuby on Rails、ReactなどでWebアプリを個人開発、SwiftでiOSアプリを個人開発やチーム開発しています。
また、ハッカソンにもよく参加しています。
インターンで行ったこと
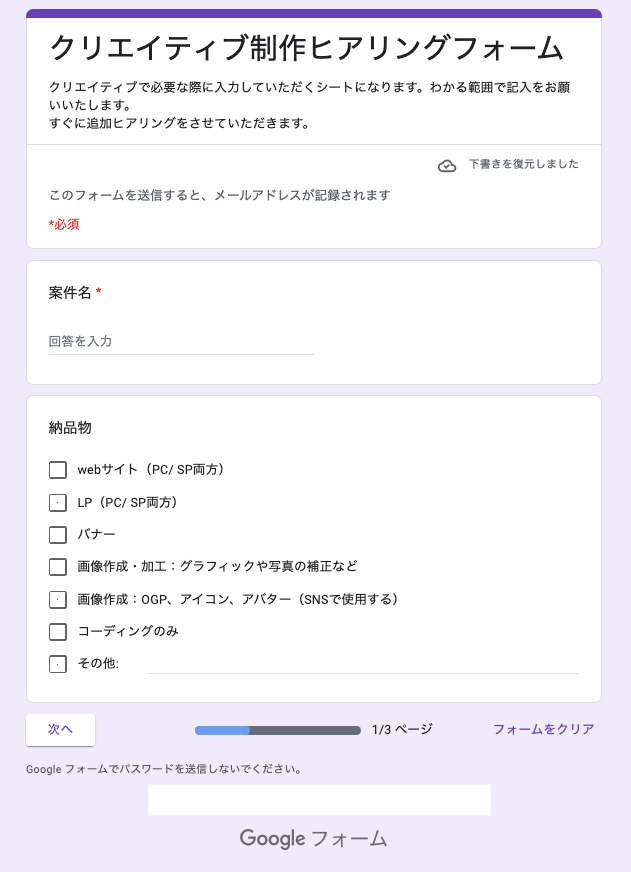
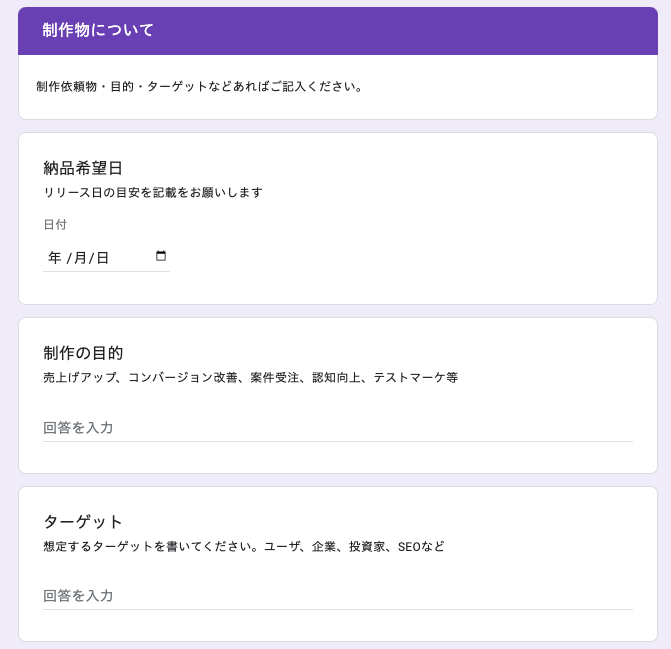
ヘルスケア事業部に配属され、「恋ラボ」「お悩み相談室」「電話占い」の3サービスのサーバーサイド開発に携わりました。
- 「恋ラボ」「お悩み相談室」のコラム記事周りの開発
- コラム一覧ページの作成や、コラム記事と無料相談ページ下にコラム最新5件を表示、TOPページにコラム最新3件を表示等
- SEO関連の画像タグの属性修正、TD(title, description)修正、カノニカルやインデックス修正
学び
インターンでは、実際にサービスを開発・運用している現場に初めて参加したこともあり、多くの学びがありました。
コードを書く上での意識
コードというのは書いた人がいなくなった後も残り続けていくものであるため、コードを書く際は、まず前提に求める挙動をすること、そして、他の人が読んだときに、分かりやすく、改修しやすいことが大事だと学びました。
また、既存のコードに手を加えるときや、コードレビューをするときなど他人のコードを読む機会がありましたが、結構大変だと感じたため、読む人の苦労を減らすということでも可読性のよいコードを書くことは重要だと学びました。
そのために、命名規則はもちろん、何を実装するためにコードを書くのか、コードのロジックを言語化して明確にしてから実装することが大切だと学びました。
チーム開発
実際にサービスを開発・運用している現場での開発方式を知り、コードレビューをもらうことで、チーム開発において、大切なこと、気をつけるべきことを学ぶことができました。
サービスを運用していくということ
当たり前かもしれませんが、サービスの運用には、様々な方々が関わっています。
エンジニア、企画、デザイナーなど様々な立場の方々が様々な視点からサービスを視て、日々より良いモノにしています。
そのため、エンジニアはコードを書くだけでなく、他の視点からの意見も聞きながら、エンジニアの視点からの意見を言っていくことで、チームとしてサービスをより良いものにしていけると学びました。
問題を解決する力
機能を実装する中で、思うように動かないことや困った時に、調べたり、人に質問したりと、解決する力が身につきました。
また、どう実装するかを考えるときに、複数のパターンを考え、メリットとデメリットを書き出すことで、よりよい実装方法を考えることが大事だと学びました。
複数のタスクを並行して処理する力
複数のタスクを並行して行わなければならない時に、優先順位づけやそれぞれにかかる時間の見積もりをしました。
見積もりは、思ってたより時間がかかることが多かったですが、複数のタスクを並行して処理していく力が身につきました。
また、当たり前ですが、きちんと連絡をすることや確認することを1つ1つやっていくことが大切だと学びました。
ミスしても、次に生かすこと
仕事をしている中で、コードレビューで指摘されたことや、ミスしてしまったことも多々ありました。
それらをただ反省するだけではなく、次同じことをしないようにどうすればいいのか考え、改善するということがとても重要だと学びました。
主体性、行動力
初めは、オンラインということや自分が質問することは相手の迷惑になるのではないかと思っていたところもあり、質問しづらかったです。
ですが、一人で詰まって時間が過ぎるよりも、人に聞くことで解決でき、相手も教えることで学びがあるということを感じ、タスクや実装についての疑問点があれば、積極的にメンターやエンジニアの方、企画の方に質問していくことができました。
その中で、指示を待っているのではなく、自分から質問するなど主体的に行動することが大切だと学びました。
技術面
実際の現場で使われている技術やコード、開発方式を知り、コードレビューをもらい、教えていただくことで、多くの知識、技術を身につけることができました。
知らない技術に対してインプットすることと、それを実装でアウトプットすることで、より多くのことを吸収できたと思います。
キャリア面
インターンでは、実際に社員の方と同じように働いていました。
そして、インターン中にエンジニアの方々とお話させていただく機会をメンターの方が作ってくださり、エンジニアになった理由、やりがい、エンジニアを続けている理由、キャリアなど、様々な質問をして、お話を聞くことができました。
その中で、今まで漠然としていたエンジニアという職業が少し明確になり、自分がどうなりたいのか、エンジニアとしてどう生きていくのかなどキャリアに関して、具体的に考えることができました。
自分の中で、将来のことで悩んでいたところがあったのですが、エンジニアの方々とお話ししていく中で、現時点での答えを見つけられたと思います。
SEOという新しい知識
SEOは、開発のなかでは、優先順位が低くなってしまいがちですが、そのサービスがユーザーに見られ、使ってもらうためにはとても重要なものです。
今回、SEOに関するタスクを行い、SEOという新しい視点からコードを見ることで、最初はカノニカルやインデックスなどおまじないだと思っていたコードも理解できるようになり、サービスを運用する上での学びとなりました。
リリースできた達成感
今回実装した「恋ラボ」「お悩み相談室」のコラム記事周りの開発では、リリースして新しいページや表示が追加されるなど、目に見える成果が大きかったため、達成感があり、とても嬉しかったです。
最後に
エキサイト株式会社での2ヶ月のインターンは、技術面でもチーム開発という面でも多くの学びがありました。
また、様々な方々とお話ししたことで、エンジニア像やエンジニアとしての生き方などキャリア面でも多くの学びが得られました。
メンターの方々をはじめエンジニアの方々、人事の方々のおかげで、とても楽しく、貴重な経験をさせていただきました。
短い期間でしたが、本当にありがとうございました。