こんにちは、エキサイト株式会社の平石です。
今回はMyBatis Generatorを利用して、ModelやMapperを自動生成する方法をご紹介します。
はじめに
DBからデータを取得するためのSQLや、DBから取得したデータを格納しておくDTO (Data Transfer Object) をいちいち作成するのは面倒です。
特に、単純なCRUDを実行したい場合や、一つのテーブルから多くのカラムを取得したい場合では、それぞれのテーブルについてSQLやコードを書いていると開発の効率が落ちてしまいます。
本ブログでは、このような負担を軽減するために、MyBatis Generatorを利用してModelやMapperを自動生成する方法を紹介します。
導入
環境
Java 21
Gradle 8.5
MyBatis Generator Version 1.4.2
DB:MySQL 8.2(ローカルのDockerで起動、ポート番号 : 3306、スキーマ : sample_schema)
実際にやってみる
今回は、Javaプログラムから実行する方法とサードパーティのGradle Pluginを利用する方法の2つをご紹介します。
どちらもビルドツールにGradleを利用します。
また、build.gradleはgroovyで記述していきます。
Javaプログラムから実行する方法
1つ目の方法はJavaプログラムから実行する方法です。
依存関係
まずは、依存関係を追加します。
plugins {
id 'java'
id 'org.springframework.boot' version '3.2.2'
id 'io.spring.dependency-management' version '1.1.4'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
java {
sourceCompatibility = '21'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter'
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
compileOnly 'org.projectlombok:lombok:1.18.30'
implementation 'org.mybatis.generator:mybatis-generator-core:1.4.2'
implementation "com.mysql:mysql-connector-j:8.2.0"
implementation "org.mybatis.dynamic-sql:mybatis-dynamic-sql:1.5.0"
implementation "org.mybatis.spring.boot:mybatis-spring-boot-starter:3.0.3"
}
tasks.named('test') {
useJUnitPlatform()
}
コメント部分以外は、spring initilizrで生成したものです。
なお、PostgreSQLに接続する場合には、以下の依存関係を追加します。
implementation "org.postgresql:postgresql:42.7.1"
設定ファイル
次に、設定ファイルを記述していきます。
MyBatis Generatorの設定ファイルはXML形式のファイルであり、公式ドキュメントにサンプルの設定ファイルが掲載されています。
これをベースに、設定をカスタマイズすると良いでしょう。
今回は以下のように設定しました。
<!DOCTYPE generatorConfiguration PUBLIC
"-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<context id="id" targetRuntime="MyBatis3DynamicSql">
<commentGenerator>
<property name="suppressDate" value="true" />
</commentGenerator>
<jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/sample_schema"
userId="sample-user"
password="sample-password">
<property name="nullCatalogMeansCurrent" value="true"/>
</jdbcConnection>
<javaTypeResolver>
<property name="useJSR310Types" value="true" />
</javaTypeResolver>
<javaModelGenerator targetPackage="com.example.mbgenerator_test.mbgenerator.modelgen"
targetProject="./src/main/java"/>
<javaClientGenerator targetPackage="com.example.mbgenerator_test.mbgenerator.mappergen"
targetProject="./src/main/java"/>
<table tableName="%"/>
</context>
</generatorConfiguration>
jdbcConnection要素にはDBへの接続情報を記述します。
こちらは、接続するDBスキーマのURL、ユーザー名、パスワードと接続に利用するドライバを設定します。
今回は、MySQLへの接続のためのcom.mysql.cj.jdbc.Driverを利用します。(PostgreSQLの場合は、org.postgresql.Driver)
ここでは、nullCatalogMeansCurrentプロパティを設定しています。
これは、バージョン8.xのcom.mysql.cj.jdbc.Driverを利用している場合、information_schemaやperformance_schema内のテーブルからもModelやMapperを生成してしまうため、この挙動を無効化するために設定する必要があるようです。
javaModelGeneratorとjavaClientGeneratorでは、それぞれModelとMapperを生成するプロジェクトやパッケージを設定することができます。
生成の対象ではなく、生成したファイルを置く「場所」を指定します。
ここでは、それぞれ./src/main/javaプロジェクト内の、com.example.mbgenerator_test.mbgenerator.modelgenとcom.example.mbgenerator_test.mbgenerator.mappergenを設定していますが、ご自身のお好みのプロジェクト、パッケージを指定してください。
基本的な設定はこれで十分ですが、他にも細かい設定を行うためのXML要素が用意されています。
例えば、ここで指定しているjavaTypeResolverのuseJSR310Typesプロパティはtrueに設定することで、テーブル内のDATE, TIME, TIMESTAMP型をJavaの型に変換する際にjava.timeのデータ型を利用するようにできます(デフォルトではjava.util.Dateを利用する)。
他の設定項目は公式ドキュメントを参照してください。
PostgreSQLでは、table要素内のschema属性で自動生成ファイルを生成したいテーブルが存在するスキーマを指定する必要があります。
さもないと、pg_catalogスキーマ内のシステムテーブル等による自動生成ファイルも生成されてしまいます。
<table schema="public" tableName="%"/>
実際に生成する
ここまでで設定は終わりましたので、実際に生成してみます。
以下のようなmainメソッドを持つクラスを作成します(設定ファイルのパス以外は、コピぺで問題ありません)。
import java.io.File;
import java.io.IOException;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import org.mybatis.generator.api.MyBatisGenerator;
import org.mybatis.generator.config.Configuration;
import org.mybatis.generator.config.xml.ConfigurationParser;
import org.mybatis.generator.exception.InvalidConfigurationException;
import org.mybatis.generator.exception.XMLParserException;
import org.mybatis.generator.internal.DefaultShellCallback;
public class MbGeneratorExec {
public static void main(String[] args) throws XMLParserException, IOException, InvalidConfigurationException, SQLException, InterruptedException {
List<String> warnings = new ArrayList<String>();
boolean overwrite = true;
File configFile = new File("./src/main/resources/config/generatorConfig.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config, callback, warnings);
myBatisGenerator.generate(null);
}
}
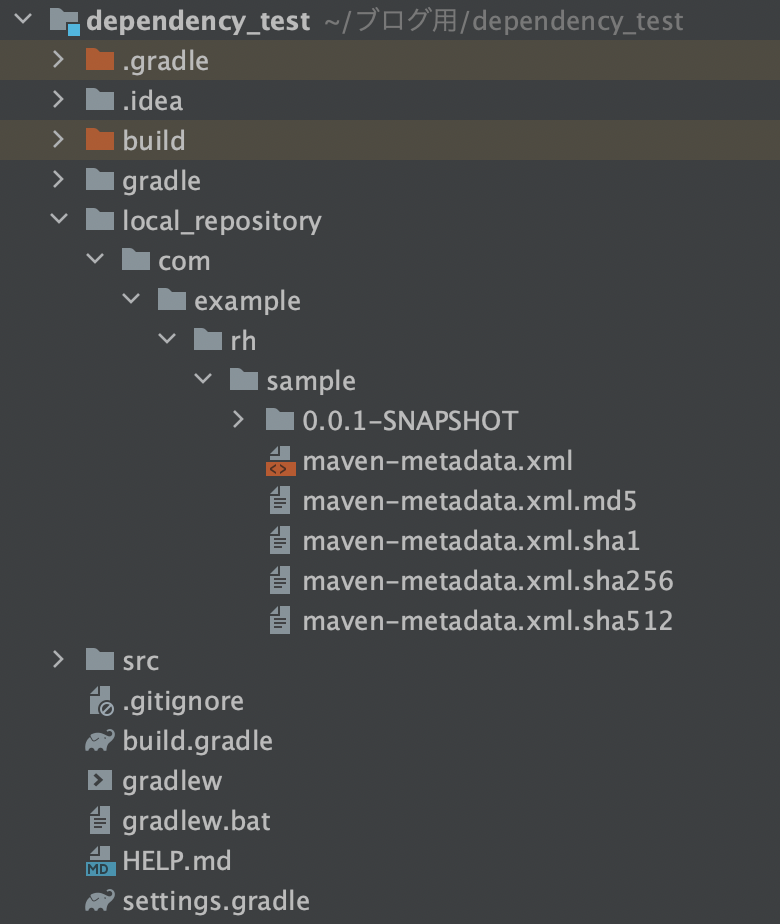
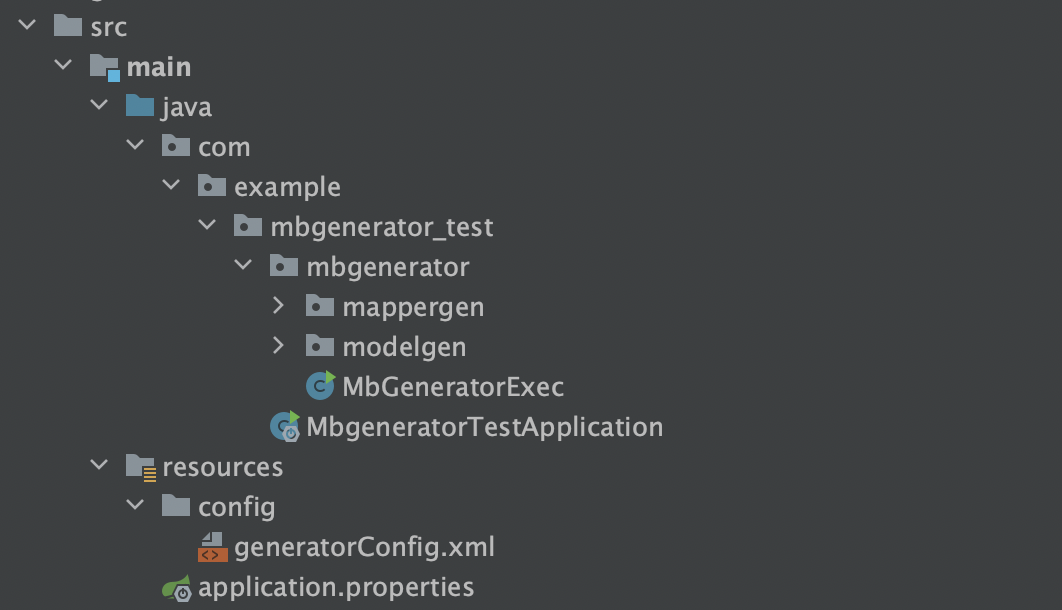
ここまでで、全てのパッケージやディレクトリ構成は以下のようになっています。
(あくまで、参考なので自由に設定して問題ありません。)
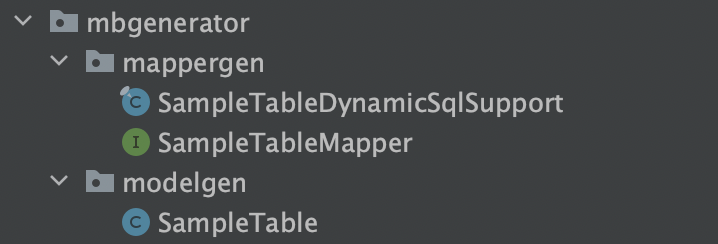
このmainメソッドを実行すれば、アクセス先のスキーマにあるテーブルのModelクラスとMapperが生成されます。
動作確認
実際に、動作が確認できなければ意味がありません。
生成したModelやMapperがJavaから利用できることを確認します。
sample_tableは以下のようなテーブルであったとします。
CREATE TABLE `sample_table` (
`sample_id` bigint NOT NULL AUTO_INCREMENT,
`sample_column` varchar(16) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`sample_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;

この時、以下のようなControllerを作成して、指定したURLにアクセスしてみます。
import java.util.Optional;
import com.example.mbgenerator_test.mbgenerator.mappergen.SampleTableMapper;
import com.example.mbgenerator_test.mbgenerator.modelgen.SampleTable;
import lombok.RequiredArgsConstructor;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
@MapperScan(basePackages = {"com.example.mbgenerator_test.mbgenerator.mappergen"})
@RequestMapping()
@RequiredArgsConstructor
public class SampleController {
private final SampleTableMapper sampleTableMapper;
@GetMapping("/index")
public String index() {
Optional<SampleTable> sampleTable = sampleTableMapper.selectByPrimaryKey(1L);
return sampleTable.map(data -> data.getSampleColumn()).orElse("何もありません");
}
}
すると、以下のように表示されMapperがうまく機能していることがわかります。

サードパーティのGradle Pluginを利用する方法
今回は、com.qqviaja.gradle.MybatisGeneratorプラグインを利用します。
依存関係
plugins {
id 'java'
id 'org.springframework.boot' version '3.2.2'
id 'io.spring.dependency-management' version '1.1.4'
id "com.qqviaja.gradle.MybatisGenerator" version "2.5"
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
java {
sourceCompatibility = '21'
}
repositories {
mavenCentral()
}
mybatisGenerator {
configFile = 'src/main/resources/config/generatorConfig.xml'
dependencies {
mybatisGenerator "com.mysql:mysql-connector-j:8.2.0"
mybatisGenerator "org.mybatis.generator:mybatis-generator-core:1.4.2"
}
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter'
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
compileOnly 'org.projectlombok:lombok:1.18.30'
implementation "org.mybatis.dynamic-sql:mybatis-dynamic-sql:1.5.0"
implementation "org.mybatis.spring.boot:mybatis-spring-boot-starter:3.0.3"
implementation "com.mysql:mysql-connector-j:8.2.0"
}
tasks.named('test') {
useJUnitPlatform()
}
1つ目の方法との違いはmybatisGeneratorという独自のブロックがあり、そこで設定ファイルのパスおよびファイル名と依存関係を指定しているところです。
設定ファイルの記述は、「Javaプログラムから実行する方法」と同じなのでそちらを参照してください。
実際に生成する
この方法では、プロジェクトのルートから以下のコマンドを実行するだけです。
./gradlew mbgenerator
これで、ModelファイルとMapperファイルが生成されました。
終わりに
今回は、MyBatis Generatorを利用して、ModelやMapperを自動生成する方法をご紹介しました。
では、また次回。
参考文献