
エキサイト株式会社のAです。
今回はAWS上のRDSのダウンサイジングに加えAurora Auto Scalingを設定しコストダウンを測った話と、その際の注意点や挙動についてご紹介させていただきます。
また、今回はGUI上での設定についてお話させていただきます。
DBインスタンスの追加・削除
現行で既に動いてるRDSを触る場合、インスタンスサイズを変更すると変更中はそのインスタンスでリクエストを捌くことはできません。
そのため、一時的に大きめのインスタンスを先に作って作業すると良いです。
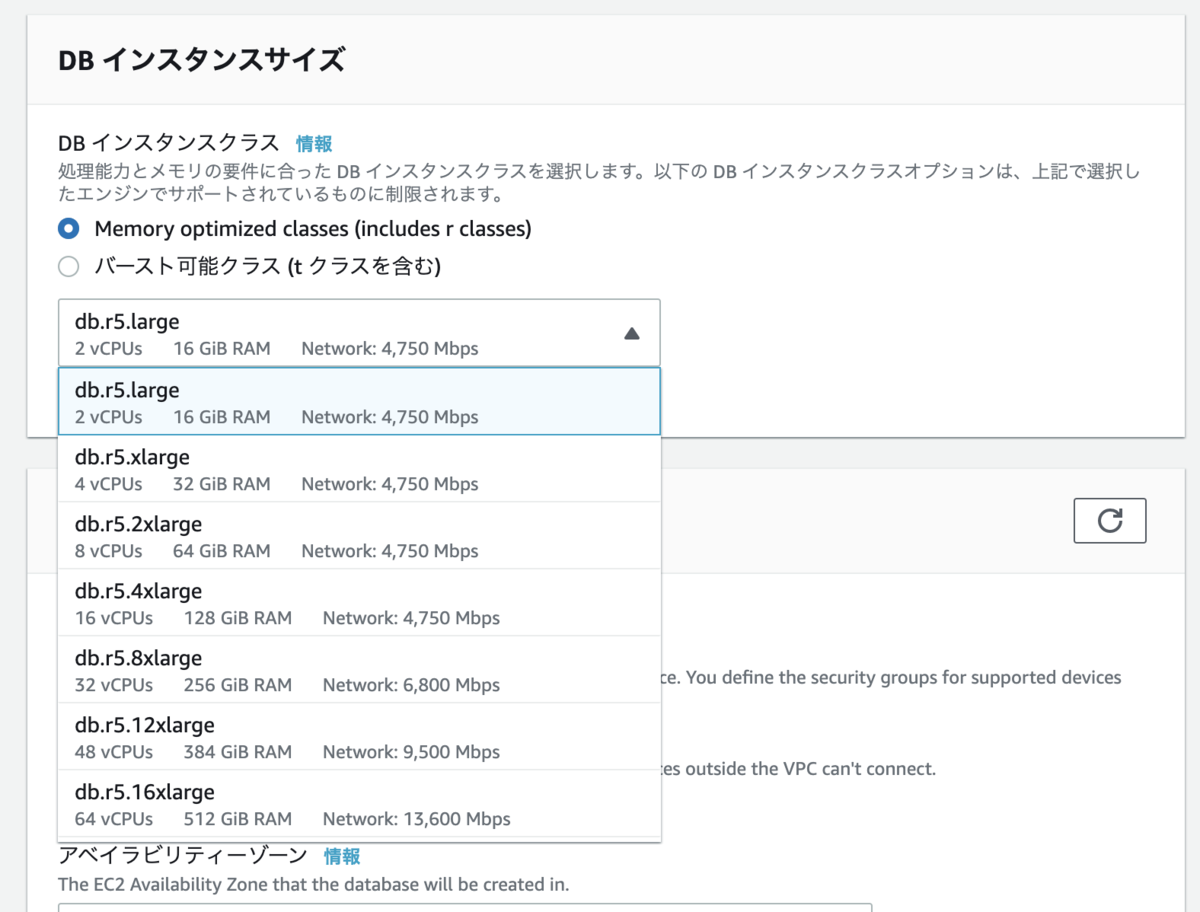 1段階〜2段階上のサイズにしておくと安心です。
1段階〜2段階上のサイズにしておくと安心です。
クラスターの設定に合わせてリーダーを作ってくれるため、一時的なリーダーの名前を決めて設定します。
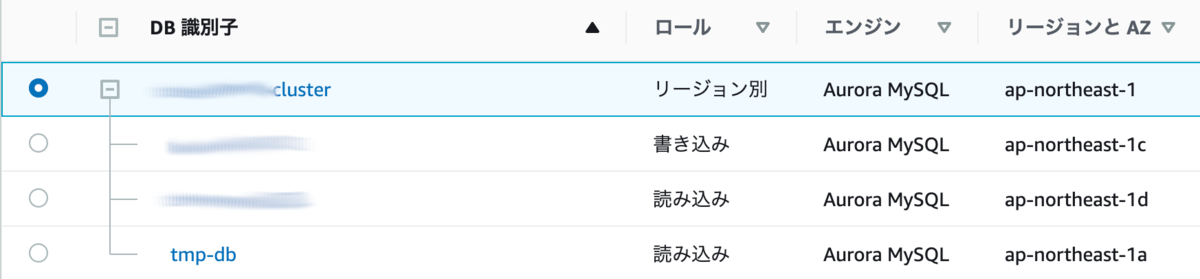 便利なことに、自動で異なるAZ配置に振り分けてくれます。
便利なことに、自動で異なるAZ配置に振り分けてくれます。
書き込みインスタンスを変える時は、事前にフェイルオーバーで読み取りインスタンスに降格させてインスタンスの変更をすると管理しやすいです。
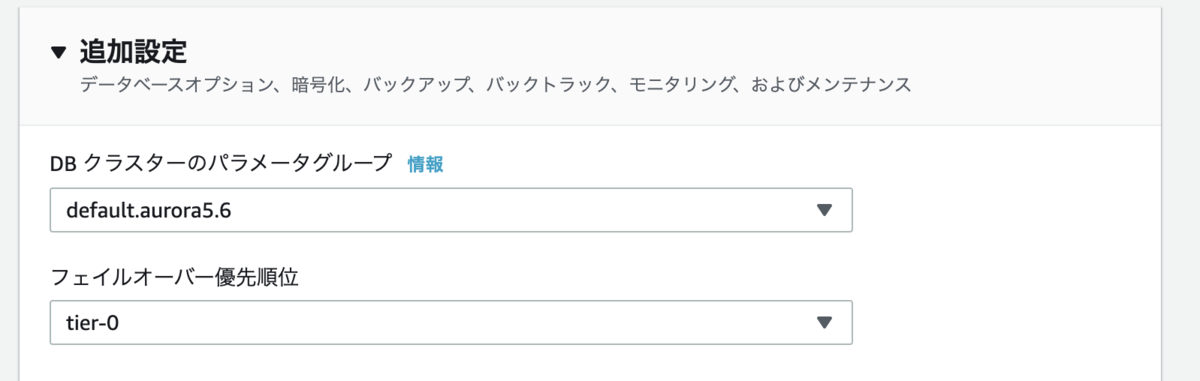 フェイルオーバーの優先順位は各インスタンスの追加設定から変更できます。
フェイルオーバーの優先順位は各インスタンスの追加設定から変更できます。
オートスケールの設定
オートスケールは、オートスケールを設定したいクラスターを選択し、[アクション]=>[レプリカのAuto Scallingの追加]で設定できます。
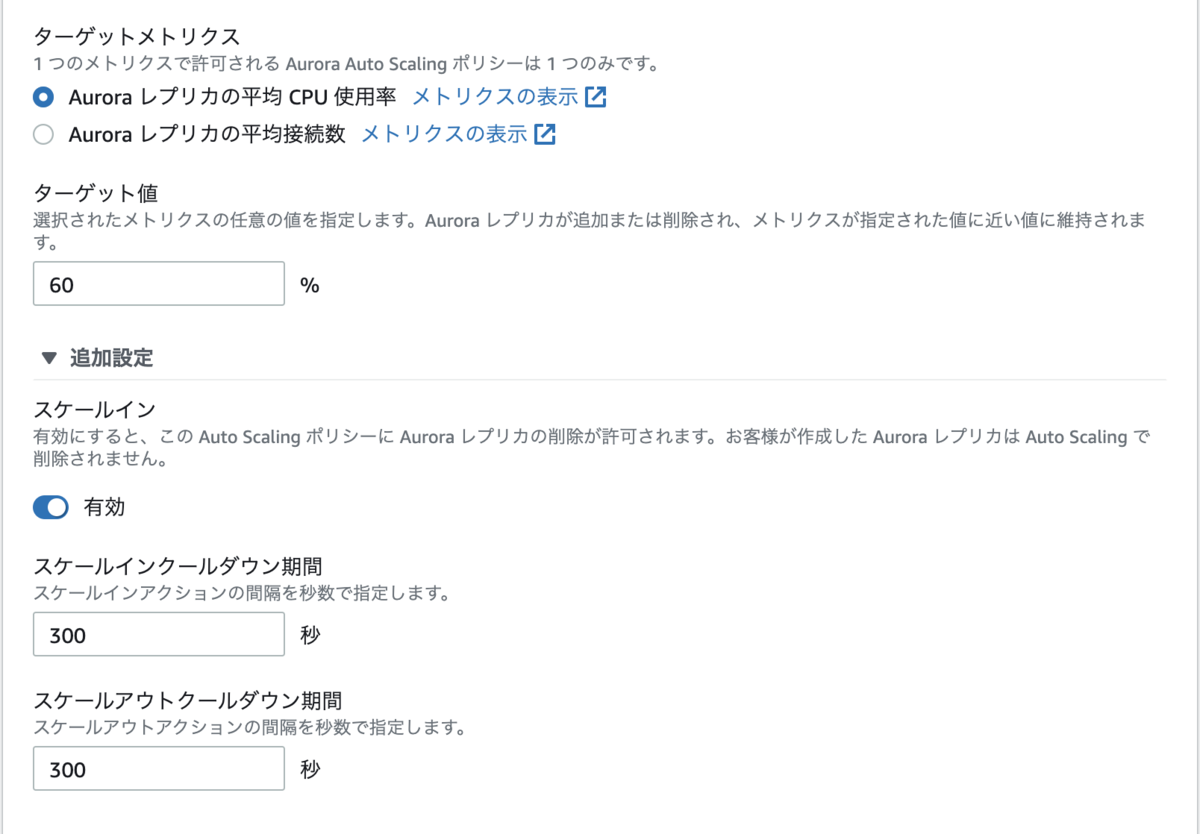
指定のターゲット値を基にインスタンスの台数が増減していきます。 CPU以外にも、DBの接続数を基にスケールイン・アウトを行うことができます。
今回のプロジェクトの場合、比較的早くアクセスが増えてしばらく高負荷の状態が続くケースが多かったです。
そのため、時間はデフォルトの300秒ではなくスケールイン60秒、スケールダウンは少し長めに300秒に設定しています
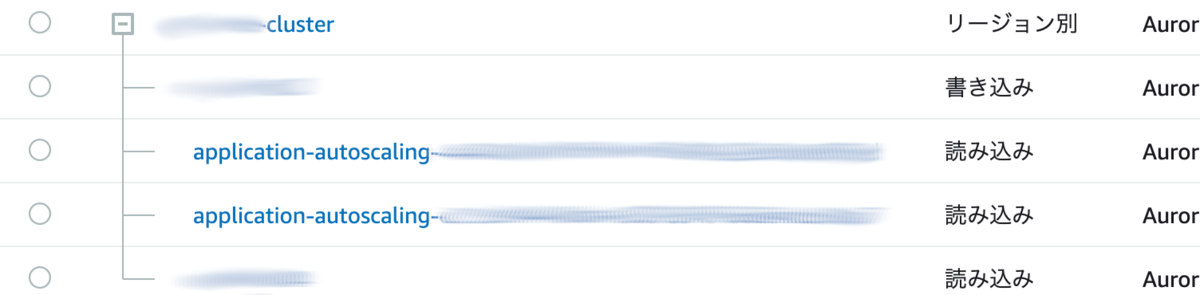 実際にオートスケールを設定すると上記のようにapplication-autoscalling-** といったインスタンスが増えます。
実際にオートスケールを設定すると上記のようにapplication-autoscalling-** といったインスタンスが増えます。
アクセスが増えたことにより、2台のインスタンスが立ち上がり大量の負荷で落ちないようになっています。
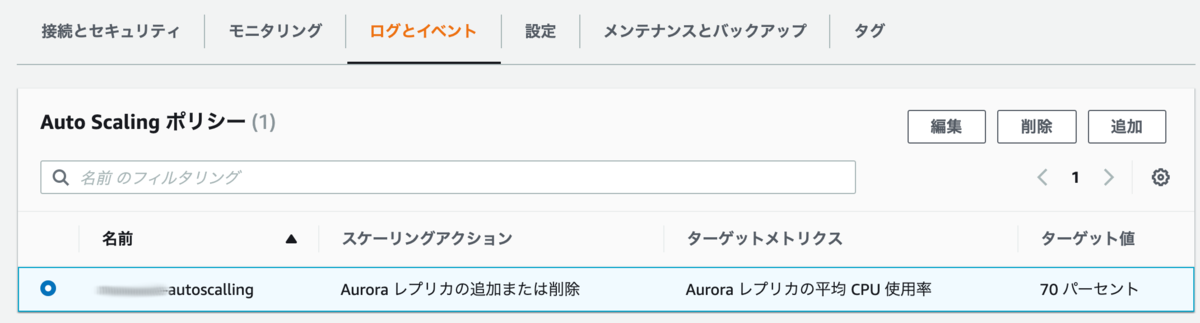
また、オートスケールの設定自体はクラスタの[ログとイベント]内の[AutoScalling ポリシー]からいつでも変更可能です。
障害時のフェイルオーバーに対応する
障害などでフェイルオーバーが起きた際、書き込みのインスタンスと読み込みのインスタンスが入れ替わってしまうことがあります。
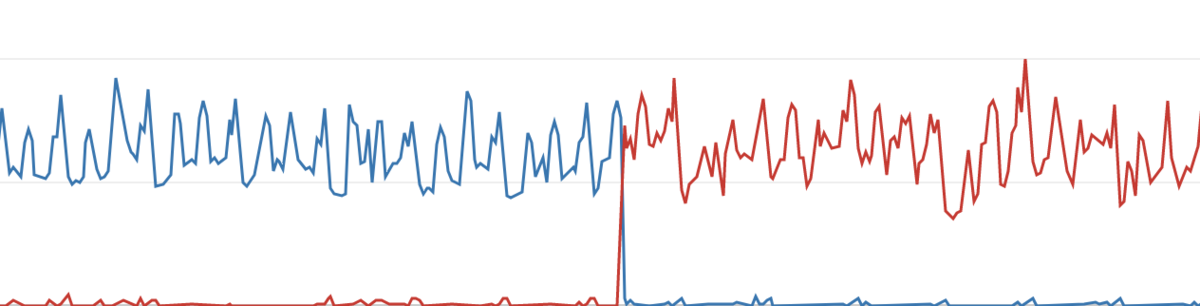
こうなると書き込みと読み込みのサイズに差があるとリクエストが捌き切れずにパンクしてしまう恐れがあります。
そのため、基本的にはmasterとreadのインスタンスサイズは同じにしておくのが望ましいです。
終わりに
今回のスケールダウンでRDSコストを当初の半分以下にまで抑えることができました。
ただしあまりにもギリギリに調整しすぎると、万が一の障害が起こった際や想定外のアクセスがきた場合に対処が難しくなるため、サイズにはある程度余裕は持たせましょう。
また、サービスにもよりますがオートスケールのターゲット値も50~60%程度が一番汎用的に使えそうです。
可用性を保ったまま低コストの運用を実現するため、サービスに合わせてうまく負荷分散できるようにチューニングしていくことが重要です。