
 こんにちは!エキサイト株式会社、SaaS・DX事業部エンジニアの岩田史門です!
こんにちは!エキサイト株式会社、SaaS・DX事業部エンジニアの岩田史門です!
エキサイトHDアドベントカレンダー7日目を担当させていただきます!
はじめに
自動音声認識 (ASR: Automatic Speech Recognition) と話者分離 (SD: Speaker Diarization) は、カスタマーサポート、自動議事録作成、音声インタフェースの改善など、さまざまな分野で活用されています。
現在開発に携わっている、FanGrowthというプロダクトでも、ウェビナーレポートという機能で活用しています!
本記事では、OpenAIのWhisperとpyannote.audioを用いた自動音声認識と話者分離技術の概要や技術的な仕組みについて解説します!
- はじめに
- 1. 自動音声認識と話者分離の概要
- 2. OpenAI Whisperの概要と技術的な背景
- 3. pyannote.audioの概要と技術的な背景
- 4. 実際にWhisperとpyannote.audioを使ってみる!(サンプルコード)
- 5. まとめ
- 6. 参考文献
1. 自動音声認識と話者分離の概要
1.1 自動音声認識(ASR:Automatic Speech Recognition)
自動音声認識とは、人間の音声をテキストに変換する技術です。これにより、会話の文字起こしや、自然言語処理と組み合わせた音声コマンドの実行が可能になります(アマゾンのAlexaやGoogleのGoogle Assistantなど)。現在の音声認識システムの多くは、ディープラーニングを活用し、ノイズ耐性や多言語対応などの機能を備えています。
1.2 話者分離(SD:Speaker Diarization)
話者分離とは、音声中の各話者を識別して、発話の区間を分割する技術です。この技術は、会議の議事録作成などで、誰が、どのタイミングで、何を話したか、を把握するために使われています。音声認識と組み合わせることで、話者ごとのテキストを生成することができます。
2. OpenAI Whisperの概要と技術的な背景
2.1 OpenAI Whisperの概要
Whisperは、2022年9月にOpenAIから発表された音声認識モデルです。以下のような特徴があります!
- 高精度なノイズ耐性
- ノイズ環境でも認識のパフォーマンスが高いです
- 多言語対応
- フリーで利用可能
- MITライセンスで公開されているため、商用利用も可能です(嬉しい🙌)
- マルチタスク
- 音声認識だけでなく、言語検出や翻訳などのタスクも実行可能です
下記の図は、同じ音声を人間がタイピングして文字起こしした場合(E~I)と、他の自動文字起こしシステム(A〜D)、Whisperが文字起こしした場合の単語の誤り率(WER:word error rate)を比較してテストしたものなのですが、同等かそれ以上の結果を出しています! (めちゃすごい!!!)
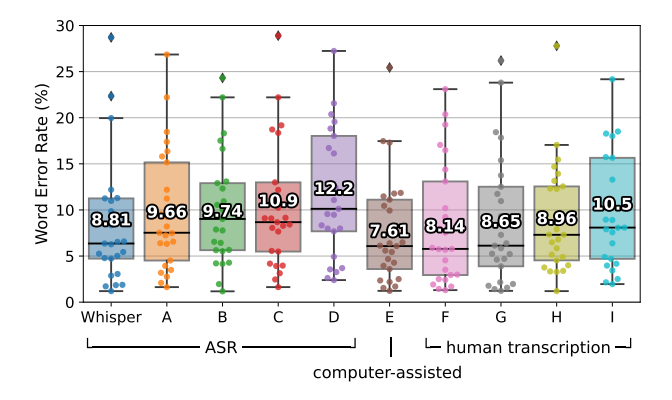
(参考)図の解釈です
- WERとは?? WERは、音声認識モデルの性能を評価するための指標で、値が低いほど認識精度が高いことを示します!
WER = (挿入単語数 + 置換単語数 + 削除単語数)/ 正解単語数
Whisper: 平均WERが8.81%で、全体的に最も低いWER(高い精度)を示しています。 他のASRモデル(A〜D)よりも安定して高精度であることがわかります。
ASRモデル(A〜D): ベンチマークとして取り上げられています! 平均WERは9.66〜12.2%の範囲。 モデルDが最もWERが高く(12.2%)、認識性能が低いことを示しています。
人間(プロの文字起こしの人)(E〜I): 平均WERは7.61〜10.5%、 コンピュータのアシストを受けたE(7.61%)が最も高精度で、人の中では最優秀。 一方で、I(10.5%)は精度が劣ることが示されています。
2.2 Whisperの技術的な背景
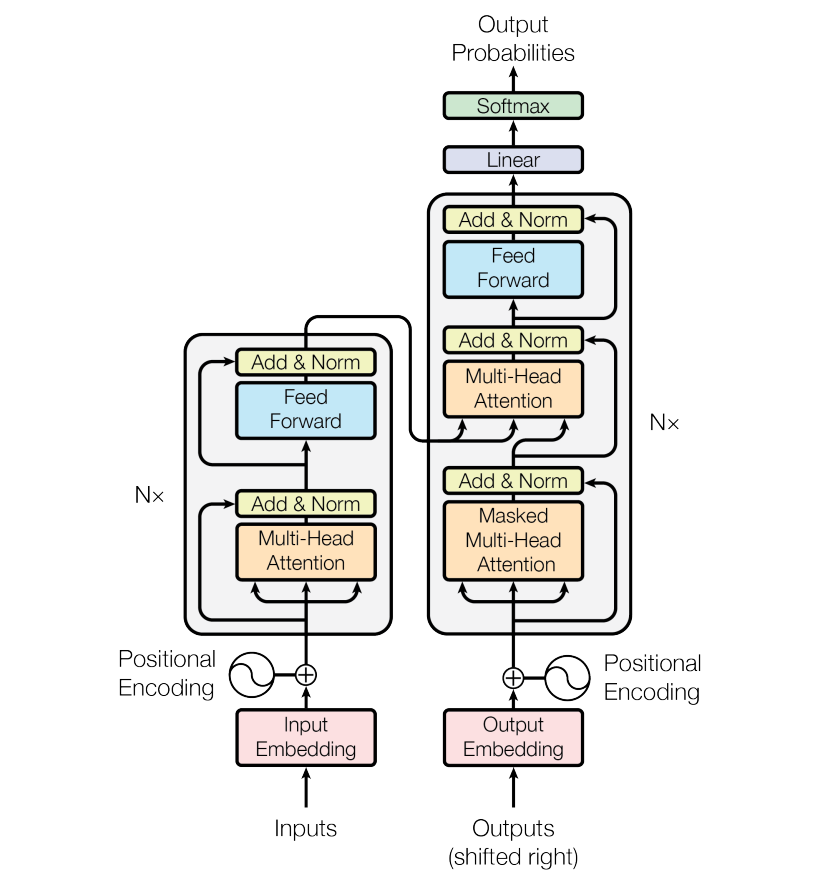
Whisperは、エンコーダ-デコーダ型のTransformerアーキテクチャを基盤としています。
エンコーダ(図の左側)の役割は、Transformerに入力されたデータを機械が理解できる特徴表現に変換することです。 入力された文字列は、エンコーダによって数値のベクトルに変換されます。
デコーダ(図の右側)の役割は、エンコーダによって特徴表現に変換されたデータを受け取り、そのデータをもとにテキストを生成することです。 これにより、数値のベクトルからテキストを生成することができます。
従来は、エンコーダとデコーダにRNNを用いていましたが、TransformerではRNNを用いないため、より高速に処理ができるようになっています。
3. pyannote.audioの概要と技術的な背景
3.1 pyannote.audioの概要
pyannote.audioは、2021年に発表された話者分離モデルです。以下のような特徴があります!
- 高精度な話者分離
- 話者分離の精度が高いです
- フリーで利用可能
- MITライセンスで公開されているため、商用利用も可能です!
3.2 pyannote.audioの技術的な背景
pyannote.audioは、話者分離や話者特定を専門としたオープンソースのPythonライブラリです。 このライブラリは、ディープラーニングフレームワークであるPyTorchを基盤としており、話者分離を簡単に利用することができます。
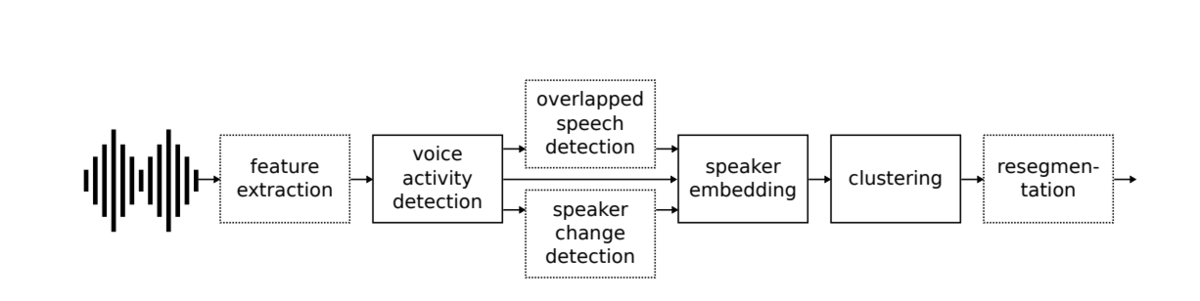
pyannote.audioは、話者分離を実現するために主に以下の3つのステップで構成されています!
音声活動検出 (Voice Activity Detection, VAD) 音声活動検出は、音声データから発話区間を検出し、ノイズや無音区間を除去するステップです。
話者埋め込み(Speaker Embedding) 話者埋め込みは、各話者の音声特徴を固定長のベクトルに変換するステップです。 音声信号をフレーム単位で処理し、それらを統合して話者ごとの特徴をベクトル化します。 このベクトルは、話者の音声的な特徴(例:声の高さ、リズム、発話スタイル)を数値的に表現したものです。 ベクトル間のユークリッド距離やコサイン類似度を用いて、異なる話者を区別します。 同一話者の埋め込みは近く、異なる話者の埋め込みは遠くなるよう学習されています。
クラスタリング(Clustering) クラスタリングは、話者埋め込みを基に、発話セグメントを話者ごとにグループ化するステップです。 クラスタリングにより、時間的に連続する発話セグメントが同じ話者に割り当てられます。
4. 実際にWhisperとpyannote.audioを使ってみる!(サンプルコード)
4.1 今回作るサンプルプログラムの流れ
WhisperとPyAnnoteを組み合わせることで、話者分離文字起こしのサンプルプログラムを作ってみましょう! 以下のステップと役割分担で実装してみます!
- 音声入力: 長時間音声を取り込み
- 話者分離 (pyannote.audio): 発話区間を話者ごとに分割
- 音声認識 (OpenAI Whisper): 各話者の発話を文字起こし
- 出力生成: 話者ごとにラベル付きのテキストファイルを生成
4.2 サンプル実行
事前準備
Hugging Faceにてアクセストークンを取得
サンプルコード内でHugging Faceにアクセスするときに、アクセストークンを利用します。
Hugging FaceにアクセスしてSignUpし、アクセストークンを取得してください。
Google Colabの準備
今回はGoogle Colabを使って実行します!
CPUではなく、GPUを使うように設定を変更してください
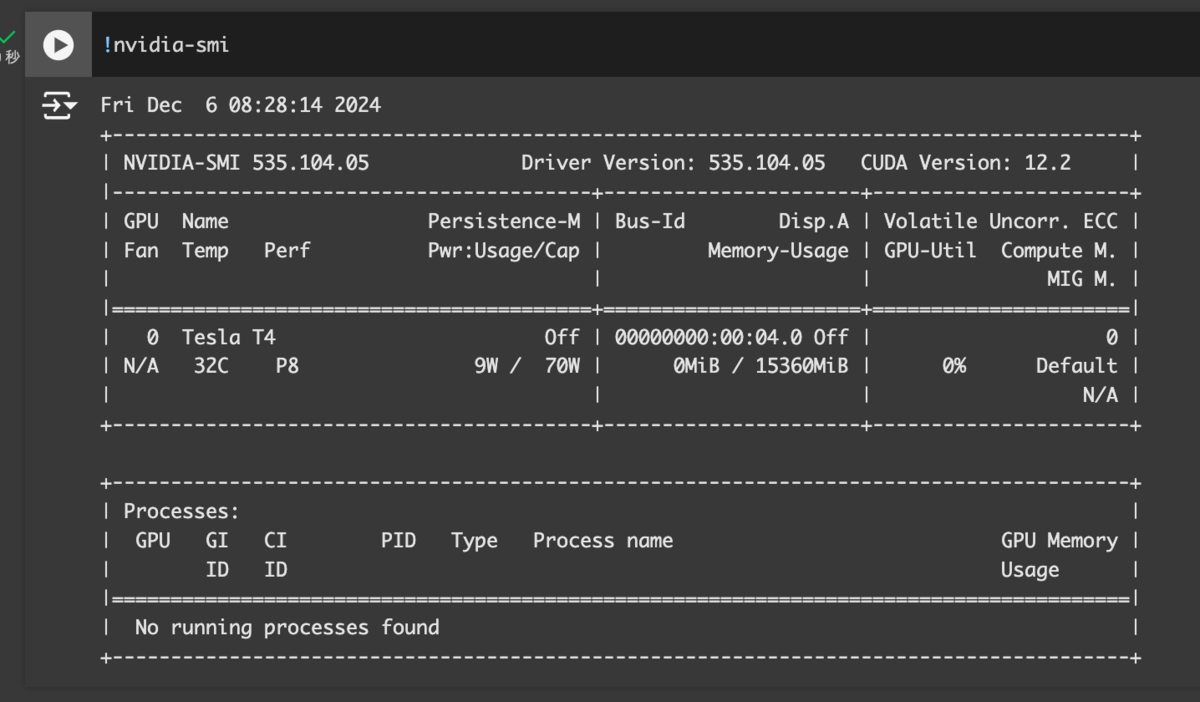
下記のようなコマンドを実行して、GPUの内容が見えていればOKです!
音声ファイルの用意
左側のフォルダのところに、音声ファイルをドラッグ&ドロップして配置してください
mp3からwavに変換
pyannoteはwavファイルしか扱えないため、ファイル形式を変換します!
サンプルコード
# 必要なライブラリのインポート from pyannote.audio import Pipeline from pyannote.audio import Audio import whisper import numpy as np # 話者分離モデルの初期化 pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization", use_auth_token="先ほど生成したアクセストークンを入れましょう!") # Whisperモデルのロード model = whisper.load_model("medium") # 音声ファイルを指定 audio_file = "sample-audio.wav" # 話者分離の実行 diarization = pipeline(audio_file) # 音声処理の初期化:16kHzのサンプリングレートに変換 audio = Audio(sample_rate=16000, mono=True) # 話者分離の結果をループ処理 # segment:発話区間の情報(開始と終了時間) # speaker: 話者の識別子 for segment, _, speaker in diarization.itertracks(yield_label=True): # 話者ごとの発話区間の音声を切り出し waveform, sample_rate = audio.crop(audio_file, segment) # 音声波形の前処理 waveform = waveform.squeeze().numpy() if waveform.ndim == 2: waveform = waveform.mean(axis=1) # Whisperが期待する、float32型に変換 waveform = waveform.astype(np.float32) # Whisperによる文字起こし segments = model.transcribe(waveform, language="ja")["segments"] subs = [] # 話者ラベル付きで結果をフォーマットして出力 for data in segments: start_time = segment.start + data["start"] end_time = segment.start + data["end"] print(f"{start_time:.2f},{end_time:.2f},{speaker},{data['text']}")
実行した時に、下記のように出力されていれば成功です!
5. まとめ
本記事では、Whisperとpyannote.audioを用いた話者分離文字起こしの概要を解説して、サンプルプログラムを作成しました!
Whisperとpyannote.audioは、それぞれの特徴を活かして、音声認識と話者分離を効果的に組み合わせることができます!
FanGrowthでは、動画や音声のデータが多いので、今後も音声認識周りの技術を活用して価値提供していきたいと思います!