こんにちは。 エキサイト株式会社のAです。
今回ElasticSearchドメインの移行を行い、さらにElasticSearch7.10からOpenSearch1.0にバージョンを上げました。
Amzon OpenSearchとは、Amazon Elasticsearch Service の後継サービスであり、Elasticsearch 7.10.2から派生したサービスです。
ElasticSearchとは互換性があり、基本的にバージョンアップ自体は容易に行えます。
※ElasticSearchのRestHighLevelClientからのアクセスができなくなり、OpenSearchのClientを使うなどの変更が必要なケースもあります。
今回、移行元のドメインのスナップショット(バックアップ)を新しいドメインにリストアして移行を行います。
OpenSearch(ElasticSearch)には、自動でバックアップを作成してくれる機能が標準で備わっていますが、ElasitcSearchの自動スナップショットは他のドメインにリストアをすることはできない為、移行元ドメインの手動スナップショットを作成する必要があります。
参考
docs.aws.amazon.com
スナップショット保存用S3バケット作成
S3コンソールで手動スナップショット保存用のS3バケットを作成
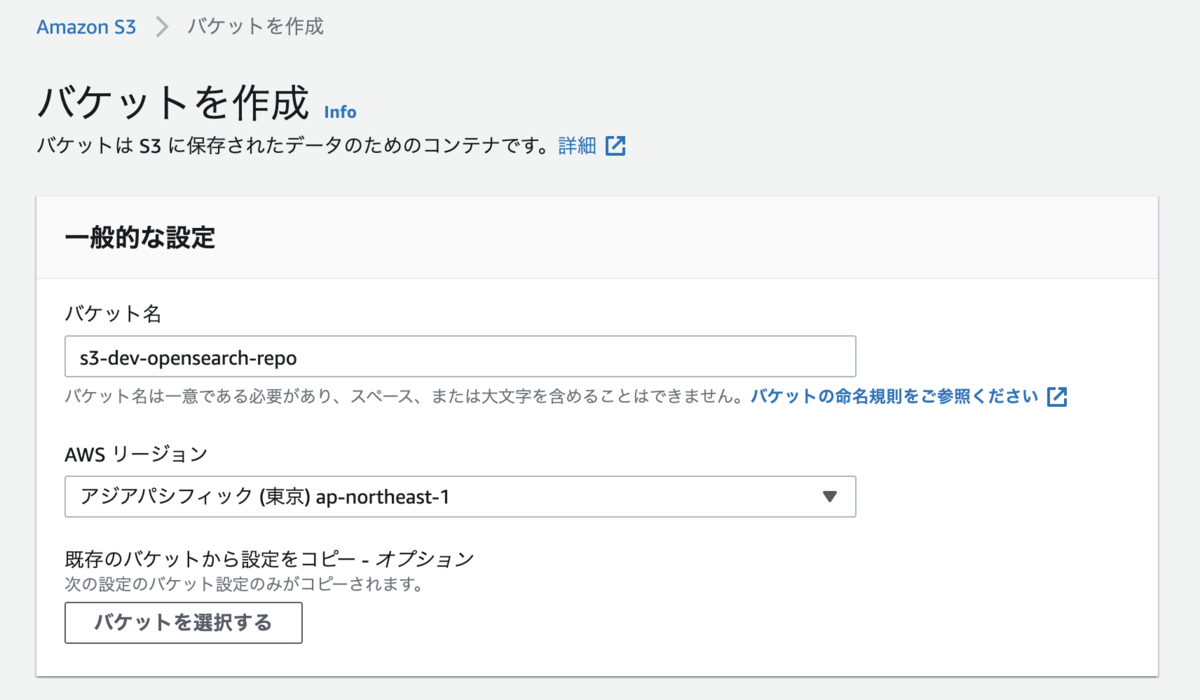
作成したS3バケットを開きプロパティから以下のようなAmazon リソースネーム (ARN)をメモしておきます。
arn:aws:s3:::s3-dev-opensearch-repo
ポリシー作成
IAM>ポリシー>ポリシーの作成 から先ほど作成したS3のポリシーを作成します。
ポリシー名例 s3-dev-opensearch-repo-policy
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::s3-dev-opensearch-repo"
]
},
{
"Action": [
"s3:*"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::s3-dev-opensearch-repo/*"
]
}
]
}
Resourceには先ほどコピーしたS3のARNを記述してください。
ロール作成
ロール名例:dev-opensearch-repo-role
ロールの作成 から、先程作成したポリシー(今回の場合はs3-dev-opensearch-repo-policy)をアタッチします。
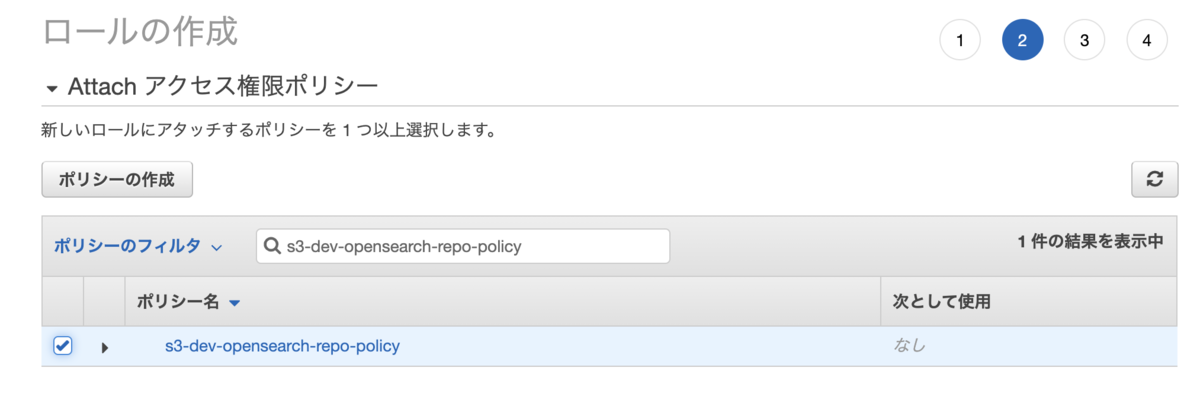
その後、作成したロールのARNをメモしておきます。
OpenSearch(ElasticSearch)用ポリシーを作成
ポリシー名例:dev-opensearch-policy
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "上記で作成したロールのARN"
},
{
"Effect": "Allow",
"Action": "es:ESHttpPut",
"Resource": "移行前ElasticSearchドメインのARN/*"
},
{
"Effect": "Allow",
"Action": "es:ESHttpPut",
"Resource": "移行後ElasticSearchドメインのARN/*"
}
]
}
その後、再度 dev-opensearch-repo-role に上記のポリシーをアタッチします。
ロールに信頼関係を追加
dev-opensearch-repo-roleの[信頼関係]タブの[信頼関係の編集]ボタンから、下記の信頼関係設定をアタッチします。
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "es.amazonaws.com"
},
"Action": "sts:AssumeRole"
}]
}
移行元、移行先ドメインそれぞれに対して下記のpythonコードでリポジトリ登録を行います。
import boto3
import requests
from requests_aws4auth import AWS4Auth
host = '[移行元・移行先ElasticSearchドメイン]/'
region = 'ap-northeast-1'
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
path = '_snapshot/[スナップショットを置くリポジトリの名前]'
url = host + path
payload = {
"type": "s3",
"settings": {
"bucket": "s3-dev-opensearch-repo",
"region": "ap-northeast-1",
"role_arn": "[作成したIAMロールのARN]"
}
}
headers = {"Content-Type": "application/json"}
r = requests.put(url, auth=awsauth, json=payload, headers=headers)
print(r.status_code)
print(r.text)
移行元のkibana,移行先のOpenSearchDashboardsでそれぞれリポジトリを確認
GET /_snapshot?pretty
結果
{
"[スナップショットを置くリポジトリの名前]" : {
"type" : "s3",
"settings" : {
"bucket" : "s3-dev-opensearch-repo",
"region" : "ap-northeast-1",
"role_arn" : "IAMロールのARN"
}
}
}
移行先ドメインからkibanaを削除
作ったばかりのドメインだと、移行元ドメインと.kibana_1が被るのでOpenSearchのダッシュボード上で下記のコマンドを実行します
DELETE /.kibana_1?pretty
スナップショット登録
import boto3
import requests
from requests_aws4auth import AWS4Auth
region = 'ap-northeast-1'
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
host = '[移行元ElasticSearchドメイン]/'
path = '_snapshot/[スナップショットを置くリポジトリの名前]/[スナップショット名]'
url = host + path
r = requests.post(url, auth=awsauth)
print(r.text)
スナップショットの確認
移行元kibanaと移行先OpenSearchDashboardsでそれぞれ下記のコマンドを実行し、スナップショットが存在しているか確認する
GET /_snapshot/[スナップショットを置くリポジトリの名前]/_all?pretty
移行先ドメインにスナップショットをリストア
import boto3
import requests
from requests_aws4auth import AWS4Auth
host = '/'
region = 'ap-northeast-1'
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
host = '[移行先OpenSearchドメイン]/'
path = '_snapshot/[スナップショットを置くリポジトリの名前]/[スナップショット名]/_restore'
url = host + path
r = requests.post(url, auth=awsauth)
print(r.text)
※ スナップショットをリストアした場合、indexのデータは全て入りますがindexテンプレートの設定まではコピーしてくれず、手動で設定し直す必要があるので注意です。
移行後ドメインに対してINDEXテンプレートを確認
GET _template/
結果
{ }








