エキサイト株式会社のみーです。
今年の3月より利用可能となったAWS Fault Injection Simulator、FISを使ってフォールトインジェクション実験をしてみました。
いわゆるカオスエンジニアリングです。フォールトインジェクション実験をするツールとしてはNetfilxのChaos Monkeyなどが有名ですが、FISを利用することでマネージドに実施できるようになりました。
さて、CFnオタクなのでテンプレートを書いてみたのですが、書き方に少しハマってしまいました。AWS CLIで実行するときも同様にハマる可能性があるため、備忘録として残しておこうと思います。
最終的なCFnテンプレート
試行錯誤の結果、以下のようになりました。RDSインスタンスを再起動させて、強制的にフェイルオーバーを発生させるという実験内容です。
Resources: FISExperimentTemplate: Type: AWS::FIS::ExperimentTemplate Properties: Description: "RDS failover experiment" RoleArn: !GetAtt IAMRole.Arn Actions: RebootInstance: ActionId: aws:rds:reboot-db-instances Parameters: forceFailover: true Targets: DBInstances: MyInstances Targets: MyInstances: ResourceType: aws:rds:db ResourceArns: - arn:aws:rds:ap-northeast-1:123456789012:db:hoge-piyo SelectionMode: ALL StopConditions: - Source: none Tags: Env: !Ref Env
ここに至るまで、1時間くらい悩みました。
書き方がよくわからない
最初はActionsの書き方(特にTargets)がわからず、公式サンプルを参考に以下のように書いていました。
Actions: RebootInstance: ActionId: aws:rds:reboot-db-instances Parameters: forceFailover: true Targets: Instances: MyInstances
すると怒られちゃうわけ。
Resource handler returned message: "Unexpected target "Instances" found in action "RebootInstance".
なるほどわからん。Instances というキーがダメなのか、MyInstances というバリューがダメなのか、よくわからん。
っで、一旦諦めてマネコンから作ってみたのですが、そこで原因判明。
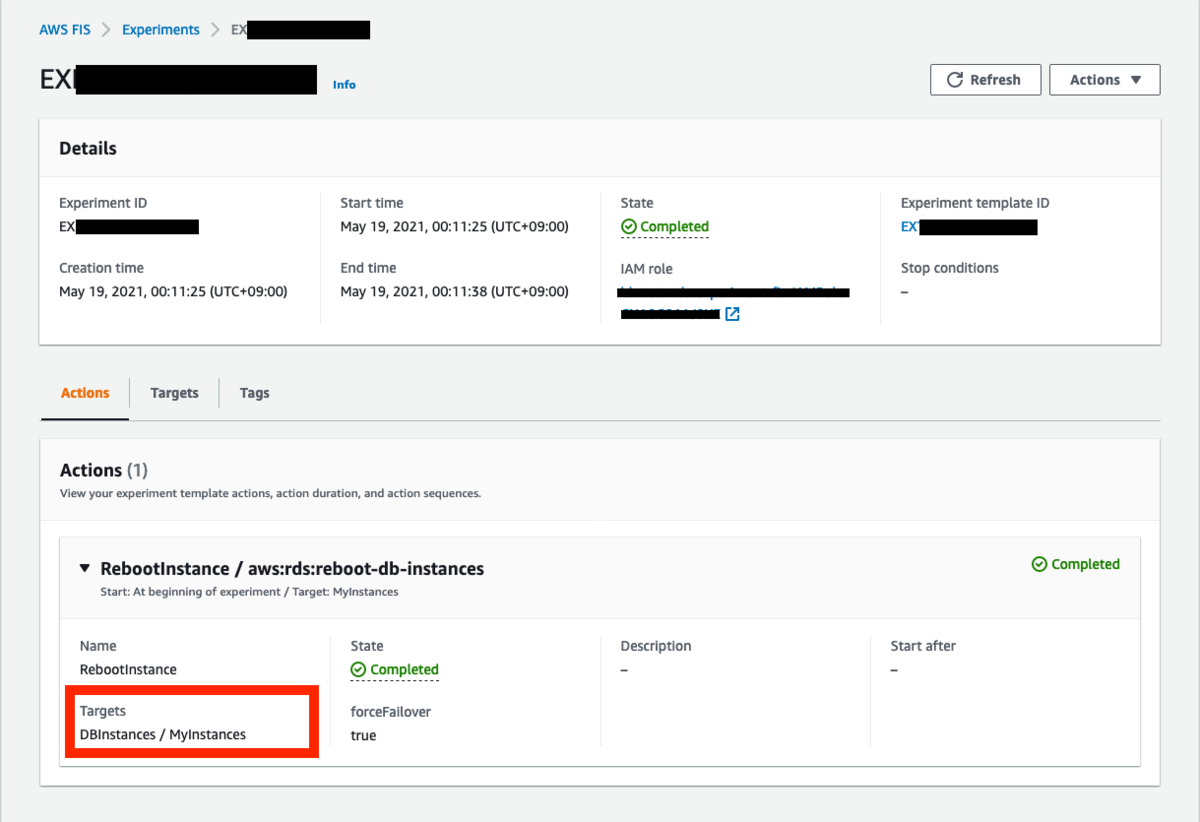
↑の赤枠内が、先ほどのActionsで指定するTargetsの Key/Value ということ。TargetのResourceTypeによって特定のキーを書く必要があるっぽい。
公式サンプルを見てみると、TargetのResourceTypeがEC2の場合には Instances と書かれていました。なるほど、だからエラーになっていたのか。
他にも少し癖がありますので、公式サンプルにはしっかりと目を通しておきましょう。
おわりに
今回の RDSインスタンスでフェイルオーバーを発生させる という実験はRDSのマネコンからも試すことができます。EC2の停止実験なども同じ、マネコンからポチポチできますね。あれ、FISいらなくね?と思いませんか?
いえいえ。そうではなくて、あくまでもカオスエンジニアリングの一環として、継続的に実験を実行していくことがFISを利用する目的だと考えます。
システムが複雑になり、内部実装がブラックボックスになって・・・そんな中で重大な障害が発生すると現場はてんやわんやです。きっと誰もが1度は経験したことあるはず。
そうならないためにも日々小さな障害を意図的に発生し続けて、「サービスを停止させない」から「障害が発生しても自動で復旧する」へと意識を変えていく必要があるのかなと思いました。
FISはそのための手段の1つ。FISを活用して、より強いシステムやアプリケーションを育てていきたいものですね。